
Acoustic Scene Analysis 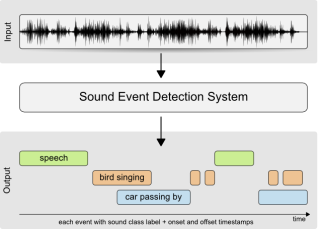
ARG is internationally recognized for its research in acoustic scene analysis, which focuses on enabling machines to interpret and understand everyday sound environments. The work spans several key areas, including acoustic scene classification, sound event detection and localization, and audio captioning. The group has collected several widely used datasets for these tasks. Applications range from smart homes and smart cities to assistive technologies for the hearing impaired. ARG also contributes to global benchmarks like the DCASE Challenge, releasing open datasets and tools to support reproducible research.
Audio Signal Processing 
ARG develops novel methods for processing audio, speech, and music signals. The group has done pioneering work on sound source separation, developing algorithms that enable decomposing complex audio mixtures into individual sources, enabling applications in speech enhancement, music analysis, and audio restoration. The group has pioneered single-channel source separation using non-negative matrix factorization. Current work leverages deep learning and self-supervised approaches for tasks such as speech separation, dereverberation, and audio representation learning. These methods improve robustness in noisy and reverberant environments, benefiting technologies like hearing aids, teleconferencing, and multimedia systems.
Speech and Cognition research
The Speech and Cognition research group studies how humans, particularly infants, learn language from raw sensory input without explicit supervision. This involves studying mechanisms for linguistic representation learning and behavioral language skills under conditions of high acoustic variability. The group develops computational models that mimic human learning processes to better understand cognitive aspects of language development. The group work also extends to machine learning applications in speech and audio processing, including self-supervised learning, speech representation learning, and multimodal modeling. Additionally, the group investigates practical applications such as infant movement tracking using wearable sensors and large-scale analysis of child-centered audio environments. Through interdisciplinary approaches combining cognitive science, linguistics, and AI, the group aims to bridge human language learning and machine learning for improved speech technologies and insights into early cognitive development.
Spatial Audio 
The spatial audio research at ARG deals with capturing, modeling, and interpreting sound in three-dimensional space using advanced signal processing and machine learning techniques. The research includes topics related to multichannel signal processing, microphone arrays, and machine learning for 3D audio. The spatial scene analysis research includes topics related to sound source localization, tracking, and distance estimation. The group also works on Ambisonics and spherical harmonics for immersive audio applications in virtual and augmented reality. The group contributions include datasets and benchmarks for spatial audio, neural beamforming techniques, and multichannel speech enhancement in dynamic scenarios. Applications range from immersive audio and virtual acoustics to assistive listening systems and context-aware devices audition.