
Abstract: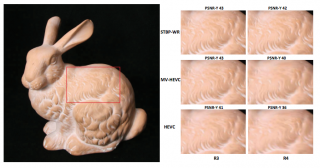
Light field (LF) acquisition devices capture spatial and angular information of a scene. In contrast with traditional cameras, the additional angular information enables novel postprocessing applications, such as 3D scene reconstruction, the ability to refocus at different depth planes, and synthetic aperture. In this paper, we present a novel compression scheme for LF data captured using multiple traditional cameras. The input LF views were divided into two groups: key views and decimated views. The key views were compressed using the multi-view extension of high-efficiency video coding (MV-HEVC) scheme, and decimated views were predicted using the shearlet-transform–based prediction (STBP) scheme. Additionally, the residual information of predicted views was also encoded and sent along with the coded stream of key views. The proposed scheme was evaluated over a benchmark multi-camera based LF datasets, demonstrating that incorporating the residual information into the compression scheme increased the overall peak signal to noise ratio (PSNR) by 2 dB. The proposed compression scheme performed significantly better at low bit rates compared to anchor schemes, which have a better level of compression efficiency in high bit-rate scenarios. The sensitivity of the human vision system towards compression artifacts, specifically at low bit rates, favors the proposed compression scheme over anchor schemes.