



As part of the SustAInLivWork project, we offer international AI Fellowships at our research group. An overview of possible research topics related to “AI for robotics” are listed below. On the SustAInLivWork homepage you will find all relevant information on the application process.
As a fellow in our program, you can engage in various hands-on research projects spanning multiple areas. You will have the opportunity to work with state-of-the-art GPUs and to extend our existing software frameworks. By bringing in your own ideas, you will conduct impactful research in various medical domains. A good understanding of robotics concepts and proficiency in programming (Python, C++ with ROS) are recommended for this internship as well as familiarity with deep learning tools.
AI for robot visual perception
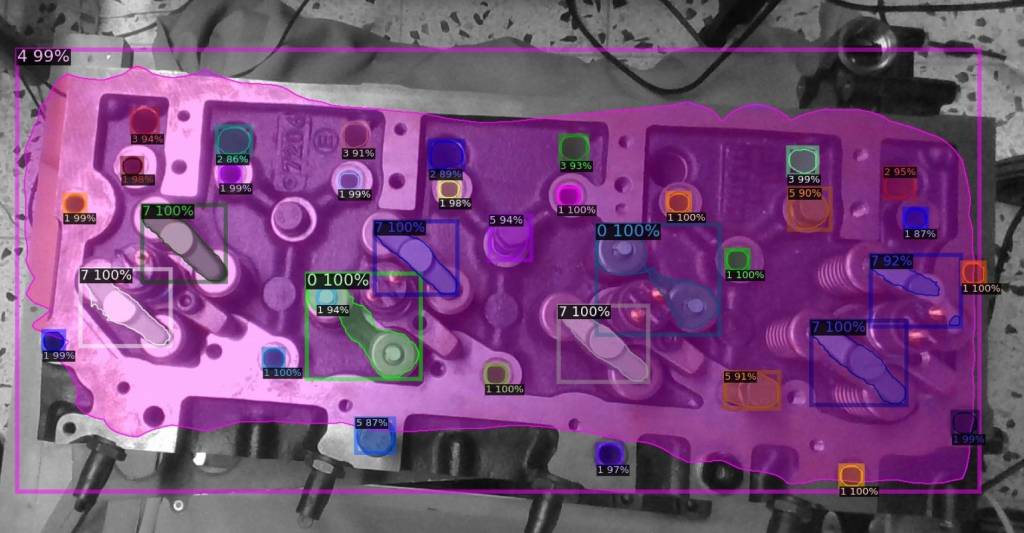
AI can be utilized for the visual perception of industrial parts, such as engine components and car batteries. Perception can be used for automation in industrial assembly by robots and human-robot collaboration, quality control and monitoring. Relevant tasks include:
- Visual data collection in the form of images from cameras (RGB, depth, etc.) and/or simulation.
- Annotation of the data to assign suitable labels and augmentation of the data expand the dataset.
- Visual perception model training and validation
- Experimental evaluation of the model with real parts and real camera
AI for human speech perception
Speech and natural language is a very effective means of communication between humans. Speech as utilized for commanding robot actions has gained interest as well with many open-source tools available (e.g. Whisper). The transition from recognized speech to robot actions is, however, not straightforward and requires careful design of interfaces and functionalities:
- Model selection of automatic speech recognition (ASR)
- Transformation of detected words to robot action framework (ROS)
- How to connect words and sentences to robot actions
- Experimental evaluation of the speech perception with real parts and real camera

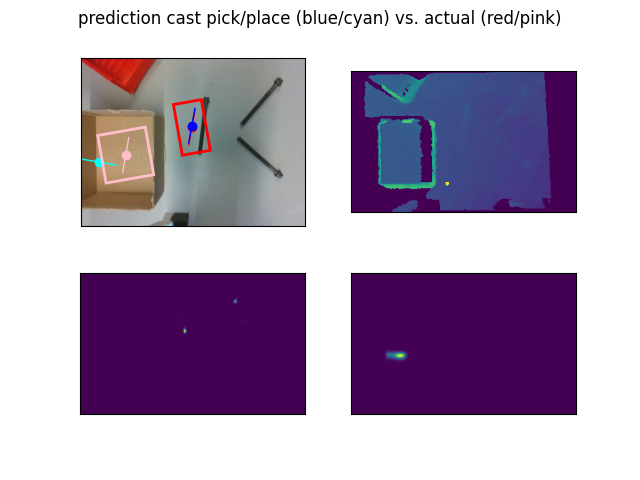
Visual language models for robotics
VLMs are AI models that combine computer vision and natural language processing (NLP) capabilities and are designed to understand images or videos and generate descriptions, answer questions, or perform various tasks based on the visual content. For robotics, they enable complex tasks to be executed based on natural language input and the current camera view of the scene. Relevant tasks include:
- Model selection of VLM, suitable to a chosen robotic task
- Selection of suitable dataset to use or which data to collect
- Experimental evaluation of the tools with simulated or real robot
Large language models for robotics
Code generation tools such as GitHub Copilot have shown to be very effectively in assisting software developers with writing and testing software. For robotics, similar tools exist that, upon input from suitable prompts, can generate python scripts for robot motion. Currently however, motion output is possible for short action sequences. Relevant tasks include:
- Test suitable existing tools such as Code as Policies
- Investigate how more complex and hierarchical actions can be generated
- Experimental evaluation of the tools with real robots