
We will be participating in ICASSP 2023 to present two papers:
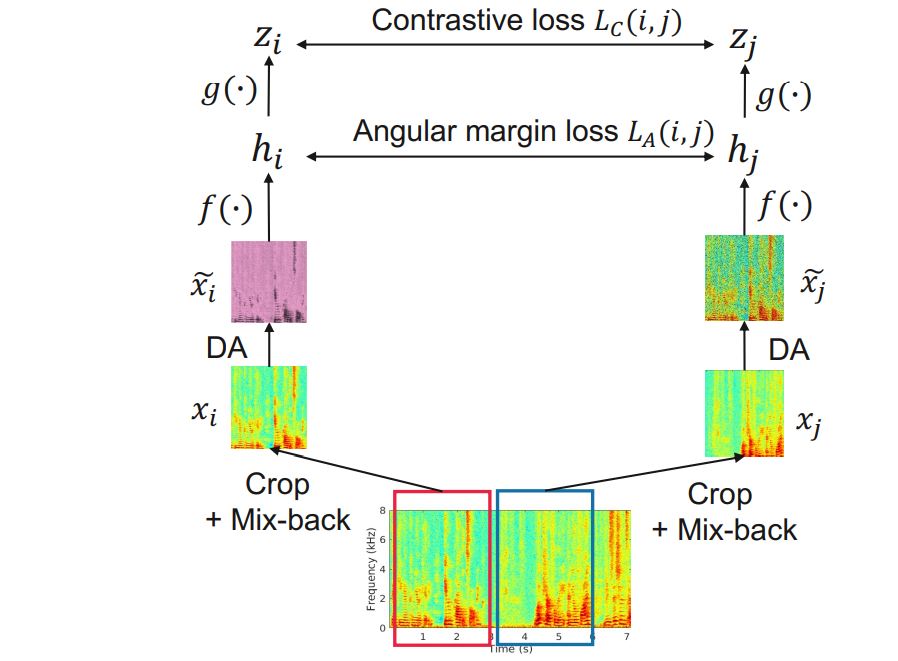
- Self-supervised learning of audio representations using angular margin loss, by Shanshan Wang, Soumya Tripathy, and Annamaria Mesaros
- Training sound event detection with soft labels from crowdsourced annotations, by Irene Martin-Morato, Manu Harju, Paul Ahokas, and Annamaria Mesaros
With the second paper, we are also publishing a dataset, MAESTRO-Real, which contains real-life recordings annotated using crowdsourcing, with soft labels estimated from multiple annotators based on their competence. The dataset will be used in DCASE 2023 challenge Task 4B – Sound event detection with soft labels, and the system presented in the paper will be the task baseline.