
A new paper entitled Self-supervised Learning of Audio Representations from Audio-Visual Data using Spatial Alignment by Shanshan Wang, Archontis Politis, Annamaria Mesaros, and Tuomas Virtanen was accepted for publication and will appear soon in IEEE Journal of Selected Topics in Signal Processing. Meanwhile you can already check it out on arxiv.
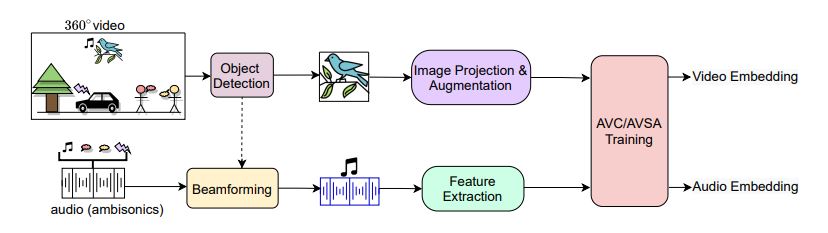
The work uses contrastive learning to learn correspondence between audio and video, with a special flavor of spatial alignment – which means that the positive pairs are selected by detecting objects in the image, and rotating the Ambisonics audio to point towards the objects, in essence connecting the objects with the sounds they produce.